ターミナルでのコマンド入力により起動するアプリのショートカット作成方法
webページからダウンロードしたUbuntu用のアプリには、アプリ起動用のショートカットが作成されず、ターミナルに起動コマンドを打ち込むことで起動するアプリが多々存在する。
しかし、UbuntuのデスクトップエディションはリッチなGUIを備えているにもかかわらずこれを活用せずターミナルを利用しなければならないのは普通の人にとっては若干不便だろう(パソコンオタクはCUIでしか操作できないことに喜びを感じることもあるかもしれないが、)。
そこで、ターミナルでのコマンド入力により起動するアプリのデスクトップアイコンを作成する方法を書きたいと思う。
ターミナル操作用シェルスクリプトの作成
テキストエディタを用いて任意のディレクトリにターミナルを操作するシェルスクリプトを作成する。
$ sudo vim usr/run_app
#!/bin/bashと、ターミナルで入力したいコマンドを記述する。
#!/bin/bash app_launch_command
シェルスクリプトに実行権限を付与する。
sudo chmod +x usr/run_app
ショートカットアイコン用の画像を用意
ショートカットアイコンとして表示させたい画像ファイルを用意し、任意のディレクトリに保存しておく。
アプリケーション一覧に表示されるデスクトップショートカットの作成
テキストエディタを用いてデスクトップショートカットファイルを作成する。
デスクトップショートカットはUbuntu18.04の場合、/usr/share/applications/ディレクトリに作成する。
sudo vim /usr/share/applications/app.desktop
ファイルには、以下の内容を記述する。
Execには起動させたいアプリケーションのpath(今回の場合は、先程作成したシェルスクリプト)を記述する。
NameやCommentには任意の名前やコメントを記述する。
Iconには、先程用意したショートカット用のアイコン画像のpathを記述する。
#!/usr/bin/env xdg-open [Desktop Entry] Version=1.0 Type=Application Terminal=false Exec=usr/run_app Name=app Comment=this is application launch shortcut icon Icon=/usr/app.png
以上でアプリケーション一覧画面にショートカットアイコンが作成され、アイコンをクリックすることで任意のアプリを起動することができるはずである。
Hardware Programming with Chisel #2 Hello, Chisel!
今回は前回のブログの続きとして、chiselでのFPGA開発環境の構築から実機での動作テストまで行いたいと思う。
前回のブログはこちら。
orihasam.hatenadiary.com
FPGA評価ボードにはXilinx社のspartan-7が搭載された、ARTY-S7を使用した。
 | ザイリンクス Artix-7 35T Arty FPGA Evaluation Kit 【AES-A7MB-7A35T-G】 価格:18,392円 |
![]()
まずは、FPGAの開発環境を構築する。
verilatorのインストール
chiselで設計した回路シミュレーションを行うC++コードを出力するために、 Verilatorをインストールする。
まず、依存パッケージをインストールする。
$ sudo apt install git make autoconf g++ flex bison
次にVerilatorのgitをクローンする。
$ git clone http://git.veripool.org/git/verilator cd verilator $ git pull $ git checkout -b verilator_3_922 refsw/tags/verilator_3_922
verilatorをビルドする。
$ unset VERILATOR_ROOT $ autoconf $ ./configure $ make $ sudo make install
vivadoのインストール
chiselで開発した回路は、VerilogHDLファイルとして出力される。この回路をxilinx製のFPGAに書き込むためにvivadoというソフトウェアを用いる。
なおvivadoのインストーラの入手には、xilinx社のアカウント登録が必要である。
まず、ダウンロードしたファイルに実行権限を付与する。
$ sudo chmod +x Xilinx_Unified_2020.2_1118_1232_Lin64.bin
実行する。
$ sudo ./Xilinx_Unified_2020.2_1118_1232_Lin64.bin
GUIのインストラクションどおりにVivado HL WebPACKをインストールする。
インストール完了後、vivadoを起動するにはターミナルで以下のコマンドを入力する。
vivado
ケーブルドライバをインストール
xillinx virtual cableのドライバをインストールする。ドライバをインストールしないとFPGAに書き込むことができない。
$ cd /tools/Xilinx/Vivado/2020.2/data/xicom/cable_drivers/lin64/install_script/install_drivers $ sudo ./install_drivers
評価ボードのボードファイルをgithubリポジトリからクローンする。今回はDigilent社のArty S7-50を用いたため、Digilent社のgithubからクローンしている。
$ git clone https://github.com/Digilent/vivado-boards.git $ sudo cp -r vivado-boards/new/board_files/* /tools/Xilinx/Vivado/2020.2/data/boards/board_files
ようやく準備が整ったので、chiselプログラミングしていく。FPGAボードとして、DIGILENT社のXilinx fpga評価ボードArty-s7-50を使用する。 まずは、評価ボードに搭載されているLEDを点灯することから始める。githubリポジトリをクローンしてchiselテンプレートを入手する。
$ git clone https://github.com/ucb-bar/chisel-template.git led_on $ cd led_on $ rm -r src/main/scala/* src/test/scala/* $ rm -rf .git $ git init $ git add .gitignore * $ vim build.sbt
build.sbtを以下のように編集する。
// See README.md for license details.
ThisBuild / scalaVersion := "2.12.12"
ThisBuild / version := "1.0.0"
ThisBuild / organization := "Individual"
lazy val root = (project in file("."))
.settings(
name := "led_on",
libraryDependencies ++= Seq(
"edu.berkeley.cs" %% "chisel3" % "3.4.1",
"edu.berkeley.cs" %% "chiseltest" % "0.3.1" % "test"
),
scalacOptions ++= Seq(
"-Xsource:2.11",
"-language:reflectiveCalls",
"-deprecation",
"-feature",
"-Xcheckinit"
),
addCompilerPlugin("edu.berkeley.cs" % "chisel3-plugin" % "3.4.1" cross CrossVersio n.full),
addCompilerPlugin("org.scalamacros" % "paradise" % "2.1.1" cross CrossVersion.full )
)
chiselプログラムの作成
verilogファイルを出力するためのchiselプログラムを作成する
$ vim ./src/main/scala/led_on.scala
以下のように記述する。
// chiselパッケージをインポート
import chisel3._
// LEDを点灯するクラス
class led_on extends Module {
/** 入出力(input/output)ポートを定義
* IOにledという出力ポートを代入
*/
val io = IO(new Bundle {
//bool値を取る出力ポートを定義
val led = Output(Bool())
})
//出力ポートをtrueにする(ポートに電位差を与える)
io.led := true.B
}
//verilogファイルを作成する
object led_on extends App {
chisel3.Driver.execute(args, () => new led_on())
}
簡単にスクリプトの解説をすると、class led_on extends Module {...}で、クラスを宣言している。
val io = IO(...)では、入出力ポートを宣言している。
new Bundle {...}には、入出力信号を含むハードウェア構成を記述している。
val led = Output(Bool())は、ledと名付けられたポートがアウトプットポートであり、boolean型の信号を持つことを記述している。
:=演算子は、演算子の右側の信号によって、左側の信号が駆動されることを示している。
true.Bはtrue値をとるBooleanを意味している。
scalaプログラムを実行する。
$ sbt run
以下のようなverilogファイルが生成される。
module led_on( input clock, input reset, output io_led ); assign io_led = 1'h1; // @[led_on.scala 12:9] endmodule
FPGAへの書き込み
先程作成したverilogファイルをvivadoで読み込み、評価ボードの制約ファイルを編集することでFPGAに書き込むことができる。制約ファイルは評価ボードメーカからダウンロードできる。
今回使用したArty-s7 50の場合は、次のgithubで提供されている。
- vivadoを起動し、create projectをクリック。

- project nameとproject locationを設定する。
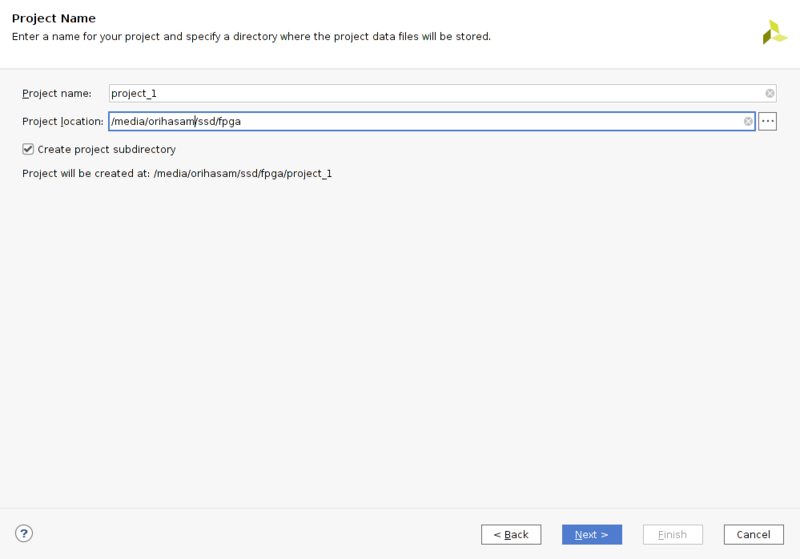
- RTL projectを選択してNext

- Add Filesで先程作成したverilogファイル"led_on.v"を選択する。Target LanguageはVerilogにしておく。
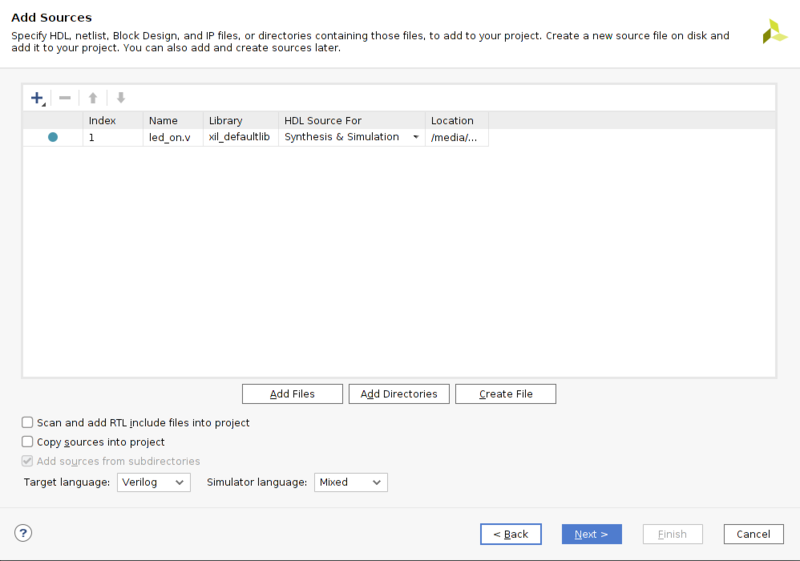
- 制約ファイルを追加する。制約ファイルは、verilogファイルに合わせて編集するため、copy constraints files into projectにチェックをつけておき、元ファイルを残しておく。

- 評価ボードを選択する。

- 制約ファイルの以下の部分を編集して、led[0]をio_ledにする。

## LEDs
set_property -dict { PACKAGE_PIN E18 IOSTANDARD LVCMOS33 } [get_ports { io_led }]; #IO_L16N_T2_A27_15 Sch=led[2]
#set_property -dict { PACKAGE_PIN F13 IOSTANDARD LVCMOS33 } [get_ports { led[1] }]; #IO_L17P_T2_A26_15 Sch=led[3]
#set_property -dict { PACKAGE_PIN E13 IOSTANDARD LVCMOS33 } [get_ports { led[2] }]; #IO_L17N_T2_A25_15 Sch=led[4]
#set_property -dict { PACKAGE_PIN H15 IOSTANDARD LVCMOS33 } [get_ports { led[3] }]; #IO_L18P_T2_A24_15 Sch=led[5]
- 評価ボードをPCとUSB接続する

- 左タブのprogram and debugからopen targetを選択し、Auto connectする。

- 左タブのRun synthesisを選択し、合成を実行する。

- 合成が完了したら、そのままRun implementationにチェックを入れて実行する。

- Implementation completedダイアログが表示されたら、generate bitstreamにチェックを入れて実行する。

bitstream generation completedダイアログが表示されたらcancelをクリック。

左タブのprogram deviceをクリックし表示される"xc7s50_0"をクリックする。
bitstream fileに先程作成したbitstream fileのパスが最初から入っているのでそのままprgramボタンをクリックしてFPGAに書き込む。

FPGA評価ボードに搭載されているLEDが点灯する。

※Open Implemented Designをクリックし、Netlistタブのled_onを右クリックしてschematicを選択すると回路図が表示される。


おわりに
今回は単純にLEDを点灯するだけの回路を作成した。次回以降はより実用的な回路作成について書いていきたいと思う。
 | 【送料無料】 Scalaスケーラブルプログラミング 第3版 / マーティン・オダースキー 【本】 価格:5,060円 |
![]()
 | 【POD】Chiselを始めたい人に読んで欲しい本 (技術の泉シリーズ(NextPublishing)) [ 七夕 雅俊 ] 価格:2,750円 |
【書評】特許情報処理:言語処理的アプローチ
はじめに
私は、仕事で知的財産に携わっているが、世界中の企業が無料で技術情報を公開してくれている“特許文献”をもっと活用したいと常日頃から思っていた。そこで自然言語処理について学び始め、このブログでもいくつか自然言語処理についての記事を書いたが、コロナ社の「特許情報処理:言語処理的アプローチ」という書籍を見つけたので、書評を書いていきたい。
 | 特許情報処理:言語処理的アプローチ (自然言語処理シリーズ) [ 藤井敦 ] 価格:3,300円 |
![]()
著者情報
本書籍は、全7章構成で、特許制度、特許実務、自然言語処理手法、特許文献特有の自然言語処理アプローチ等について記載されており、複数人の共同執筆である。全体を通しての監修は、東京工業大学の奥村学教授が行っている。研究室のホームページ*1を参照すると、文書要約などについての研究を行っているようであった。
第1章は、特許実務における情報処理システムについて書かれており、IRD国際特許事務所の所長・弁理士である谷川英和氏と、東京工業大学で情報検索などの研究を行っている*2藤井敦准教授が担当している。
第2章は、特許検索について書かれており、第1章に引き続き、藤井准教授が担当している。
第3章は、特許分類について書かれており、日立製作所勤務兼、東京工業大学精密工学研究所客員教授で、特許文献読解支援などの研究を行っている*3岩山真氏が担当している。
第4章は、特許分析について書かれており、中央大学で、テキストからの情報の自動抽出などの研究を行っている*4難波英嗣教授が担当している。
第5章は、特許翻訳について書かれており、筑波大学で機械翻訳などの研究を行っている*5山本幹雄教授と、NICTで翻訳技術について研究している内山将夫主任研究員が担当している。
第6章は、特許のための自然言語処理について書かれており、岩山氏、谷川氏、難波教授、藤井准教授が担当している。
第7章は、特許制度や特許実務について書かれており、谷川氏が担当している。
第1章について
第1章は、特許実務(特許庁、企業知財部、特許事務所での実務)の各フェーズの簡単な解説と、それぞれのフェーズにおいて自然言語処理技術がどのように活用されているか、またどのような自然言語処理を利用した支援が有効か、現状どのような課題が存在しているかについて簡単に説明している。
この章は、特許に関わる実務を行っている者にとっては既知の内容であり、読み飛ばしても良いだろう。しかし、今まで自然言語処理の研究を行ってきていた人が、これから特許を対象に自然言語処理を行おうと考えている場合は、この章に書いてあることは理解しておく必要があると思われる。
第2章について
第2章は、一般的な情報検索システムの役割、構成要素、ベンチマークテストなどについて記載されている。ベンチマークテストについての記載はやや冗長な気もするが、特許検索を行う上で、先人達がどのような要素を用いてどの程度の信頼性のある結果を出すことができたのかを知ることができるので、自然言語処理を専門で扱っていた人であっても、特許という独特の文献を対象に今後言語処理を行おうとしている人にとって非常に有意義な内容であると思われる。
第3章について
第3章では、文書分類について記載されている。特許分類の世界標準であるIPCから、日本特有の技術分野における分類まで反映したFI(File Index)やFタームなどの特許分類についての情報や、実務において特許の分類がどのように使われているのか、ナイーブベイズ法、k-NN(k-Nearest Neighbor:k近傍法)、SVM(Support Vector Machine)などの分類手法の概要と特許分類における利用について書かれている。特許分類に利用できる分類手法は最新の手法までカバーされているわけではないが、特許分類をするためにどのようなことを考えるべきなのかがまとまっており、非常に有用な章であった。
第4章について
第4章では、テキスト分析について幅広く書かれている。この章で扱うテキスト分析の対象は特許のみならず、論文も対象にしており、技術動向や重要技術をテキストマイニングにより見つけ出す手法が書かれている。一部、特定の特許検索サービスの宣伝かと思うような記載もあるため、若干内容は薄いように感じた。
おわりに
本来は1つの記事で1冊の書評をずべて書き切りたいところだが、読書に使える時間が限られているため次章以降は後々更新していこうと思う。自然言語処理で特許文献を扱うために「特許情報処理:言語処理的アプローチ」を買うか悩んでいる方の参考になれば嬉しい。
自然言語処理で映画レコメンドする
 映画を探す手法の提案ーーー
映画を探す手法の提案ーーー
ある映画から、特定のジャンルの要素を減らし、別のジャンルを足すことにより、自分が探している雰囲気に近い映画を提案しようと思う。なお、この記事で作成したレコメンドエンジンは、WEBアプリとして公開しているので、ぜひ触ってみて欲しい。
方針
上記目標をコンピュータによって実現するためには、まず、コンピュータが映画の内容やジャンルを理解することが必要である。残念ながら、映画の内容やジャンルを日本語(自然言語)で与えてもコンピュータには理解することができない。そこで映画の内容と映画のジャンルをベクトル(コンピュータでも理解可能な数値表現)で表す。
映画の内容とジャンルをベクトル化できれば、最終的に提案する映画は以下の式で算出できる。ここで太字はベクトルであることを表している。
movie 1 + movie 2 = recommended movies
算出されたベクトルに近いベクトルを持つ映画を提案すれば、ユーザーの好みに近い映画を提案できるはずである。
映画内容のベクトル化
まずは、映画の内容のベクトル化(=分散表現を獲得)したいと思う。分散表現の獲得のためには当然ながら、映画の内容が記録されたデータを入手する必要がある。
今回は映画の内容を表すデータとして、Wikipediaの記事データを用いる。Wikipediaの各映画記事のあらすじをベクトルで表現すれば、映画の内容を表すベクトルとしてある程度信頼性の高いデータになると考えられる。さらに、テキストデータであれば一つ一つのデータ量も少なく、無料で手入可能なため、個人の実験用として適切なデータだと考えられる。
Wikipediaのデータを入手
まずはデータがなければ何も始められないので、Wikipediaのデータを入手しようと思う。Wikipedia日本語版の記事データは、https://dumps.wikimedia.org/jawiki/latest/で入手可能である。Pythonを使用している人であれば、スクレイピングによりデータを取得するという方法を思い浮かんだ人もいると思うが、Wikipediaでクローラによるデータ収集を行いサーバーに負荷をかけると、アクセス禁止措置や法的措置を取られる可能性がある。データ取得に際は必ず、上記リンクからデータをダウンロードすること。
Wikipedia日本語版の全記事データが、上記リンクのjawiki-latest-pages-articles.xml.bz2をダウンロードすることで入手できる。
Wikipediaのデータをテキストファイルに変換
https://dumps.wikimedia.org/jawiki/latest/からダウンロードしてきたデータはxmlファイルなので、これをそのままxmlパーサなどを用いて解析することで利用することもできるが、手間が掛かる。今回はOSSであるwikiextractorとwikiextractor2sqliteを用いてデータをテキストファイル化して扱いやすくする。
以下のコマンドで、wikiextractorをダウンロード、実行しテキストファイルを入手する。
$ git clone https://github.com/attardi/wikiextractor $ python -m wikiextractor.WikiExtractor jawiki-latest-pages-articles.xml.bz2
不要なデータを削除
まず、得られたデータは各記事が
#open text file
with open(path) as f:
s = f.read()
'''
xmlパーサは親タグが存在しないとパースできないため、親タグを付与する。
'''
#add root tag
s = '<wiki>' + s
s = s + '</wiki>'
#xml parse
root = ET.fromstring(s)
#list for store the wiki data
doc = []
#get data that tag is doc
for l in root.iter('doc'):
doc.append(l.text)
次に、映画に関する記事以外の記事データをすべて削除する。wikipediaのデータを観察すると、映画の記事には、映画という単語が記事内に含まれるとともに、あらすじ、ストーリーを紹介する節が存在する。そこで、テキスト中に、映画という単語が存在しかつ、見出しの「ストーリー」または「あらすじ」が存在すれば映画に関する記事であると推定し、データを作成した。
movie = [s for s in doc if '映画' in s and
'\nあらすじ.\n' in s or '映画' in s and '\nストーリー.\n' in s]
映画のタイトルと、あらすじの取得は以下のコードで行った。
for m in movie:
if '\nあらすじ.\n' in m:
'''
タイトルを取得
タイトルのあと、改行が2つ挿入されているため、そこで分割。
'''
t = m.split('\n\n')
t_txt = t[0]
#邪魔な改行コードを削除
t_txt = t_txt.replace('\n', '')
title.append(t_txt)
'''
あらすじ部分のみ抽出
あらすじ、で分割し、あらすじパート終了後で更に分割
'''
d1 = m.split('\nあらすじ.\n')
d2 = re.split('\n.*\.\n', d1[1])
s_txt = d2[0]#あらすじ
story.append(s_txt)
elif '\nストーリー.\n' in m:
'''
タイトルを取得
タイトルのあと、改行が2つ挿入されているため、そこで分割。
'''
t = m.split('\n\n')
t_txt = t[0]
#邪魔な改行コードを削除
t_txt = t_txt.replace('\n', '')
title.append(t_txt)
'''
あらすじ部分のみ抽出
あらすじ、で分割し、あらすじパート終了後で更に分割
'''
d1 = m.split('\nストーリー.\n')
d2 = re.split('\n.*\.\n', d1[1])
s_txt = d2[0]#あらすじ
story.append(s_txt)
取得したデータをpandasのデータフレームに変換すると、最終的には18036行のデータベースが作成できた。コードの全体は、githubで公開している。
title story 0 スポンティニアス・コンバッション/人体自然発火 1955年、1組の若い夫婦がネヴァダ砂漠で軍によって行われたある実験の実験台となった。それは... 1 レッド・ノーズ・デイ・アクチュアリー 以下では初放送された英国版のあらすじを述べる。作品は前作から13年後の2017年3月に設定さ... 2 マンジル・マンジル マルホトラ家の一人娘シーマ。父は娘の行く末を決め、彼女もそれを受け入れた。しかし彼女は旅先で... 3 族譜 (映画) 日本統治時代の朝鮮、大地主の一族の長であるソル・ジニョン(薛鎮英)は、創氏改名に従って一族の... 4 プール (映画) ニューヨーク郊外の高校に通うベンは、仲のいい友人も理想的な恋人エイミーもいて、水泳部ではオリ... ... ... ... 18031 サクリファイス (1986年の映画) 舞台はスウェーデンのゴトランド島。舞台俳優の名声を捨てたアレクサンデルは、妻アデライデと娘マ... 18032 ハッピーバースデー 命かがやく瞬間 あすかは母・静代の精神的虐待を受け続けていたが、それでも「母に愛されたい」と思っていた。しか... 18033 プライベート・ベンジャミン 甘やかされて育った金持ちの娘ジュディ・ベンジャミンは、新婚初夜に新郎に腹上死されるという不運... 18034 レ・ミゼラブル (1998年の映画) 囚人のジャン・バルジャンは、窃盗の罪で19年間に及ぶ重労働を課された後に保釈されたが、行く先... 18035 終りなき戦い 超光速航法「コラプサー・ジャンプ」を発見した人類は、その活動の幅を宇宙へと大きく広げていた。... [18036 rows x 2 columns]
テキストを整形
入手したあらすじテキストを扱いやすくするために、前処理を行い整形する。前処理では、改行コードの除去、数値データの削除が行われることが多い。数値データが重要でない場合、数字を一律0に変換する処理が行われる場合もあるが、映画のあらすじの場合、数字情報が時代設定等に影響を与えている可能性があるため、今回は、数値データに対する処理は行わず、改行コードの除去のみを行う。
for i in range(len(df)):
text = df.at[i, 'story']
#改行削除
text = text.strip()
次に、テキストを形態要素解析により単語単位に分割する。形態要素解析にはMeCabというライブラリと、NEologdという辞書を用いる。
MeCabをインストールする。
$ sudo apt install mecab $ sudo apt install libmecab-dev $ sudo apt install mecab-ipadic-utf8
NEologdをインストールする。
$ git clone https://github.com/neologd/mecab-ipadic-neologd.git $ cd mecab-ipadic-neologd $ sudo bin/install-mecab-ipadic-neologd
$ pip install mecab-python3
形態要素解析を実行する。
for i in range(len(df)):
mec = MeCab.Tagger('-Owakati -d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd')
text = df.at[i, 'story']
#形態要素解析実行
df.at[i, 'story'] = mec.parse(text)
形態要素解析の結果を見てみると、かなり良い精度で分割できていることが分かる。
title story 0 スポンティニアス・コンバッション/人体自然発火 1955年 、 1 組 の 若い 夫婦 が ネヴァダ 砂漠 で 軍 によって 行わ れ た ... 1 レッド・ノーズ・デイ・アクチュアリー 以下 で は 初 放送 さ れ た 英国 版 の あらすじ を 述べる 。 作品 は 前作 ... 2 マンジル・マンジル マルホトラ 家 の 一人娘 シーマ 。 父 は 娘 の 行く末 を 決め 、 彼女 も それ... 3 族譜 (映画) 日本統治時代の朝鮮 、 大 地主 の 一族 の 長 で ある ソル ・ ジニョン ( 薛 鎮... 4 プール (映画) ニューヨーク 郊外 の 高校 に 通う ベン は 、 仲 の いい 友人 も 理想 的 な ... ... ... ... 18031 サクリファイス (1986年の映画) 舞台 は スウェーデン の ゴトランド 島 。 舞台俳優 の 名声 を 捨て た アレクサン... 18032 ハッピーバースデー 命かがやく瞬間 あすか は 母 ・ 静代 の 精神的 虐待 を 受け 続け て い た が 、 それでも 「... 18033 プライベート・ベンジャミン 甘やかさ れ て 育っ た 金持ち の 娘 ジュディ ・ ベンジャミン は 、 新婚 初夜 ... 18034 レ・ミゼラブル (1998年の映画) 囚人 の ジャン・バルジャン は 、 窃盗 の 罪 で 19年間 に 及ぶ 重労働 を 課さ... 18035 終りなき戦い 超光速航法 「 コラプサー ・ ジャンプ 」 を 発見 し た 人類 は 、 その 活動 の... [18036 rows x 2 columns]
単語の分散表現の獲得
単語の分散表現の獲得のためには、様々な手法が考えられるが、今回はgensimというライブラリを用いてword2vecによる分散表現を生成しようと思う。
word2vecは、skip-gramまたはCBOWというモデルを用いて学習を行う手法である。CBOWのタスクは、目的単語の周辺にある単語から目的単語を推測するという訓練を行うニューラルネットワークである。一方、skip-gramのタスクは、ある単語から、その周辺にある単語を推測するという訓練を行うニューラルネットワークである。skip-gramのほうが困難な問題について訓練を行っていることから推測されるように、skip-gramのほうがCBOWよりも学習に時間がかかるが、より精度の高い分散表現を獲得できると言われている。
まずは、gensimライブラリをインストールしておく。
pip install gensim
gensimで文章を読み込み、学習するために全あらすじデータをつなげたテキストファイルを作成する。
import pandas as pd
#pandas dataframe読み込み
df = pd.read_pickle('./morpho_data.pkl')
#word2vec用のテキストデータ作成
sentence = ''
for i in range(len(df)):
sentence += df.at[i, 'story']
#改行削除
sentence = sentence.replace('\n', '')
with open('./sentence.txt', mode='w') as f:
f.write(sentence)
gensimでword2vecによる分散表現を算出するためのコードは非常に簡単である。
from gensim.models import word2vec
import pandas as pd
path = './sentence.txt'
#テキスト読み込み
sentences = word2vec.LineSentence(path)
#実行
model = word2vec.Word2Vec(sentences, sg=1, size=200, min_count=1, window=3)
#ベクトル保存
model.save('./movie.model')
word2vec.Word2Vec()に渡す引数は、sentencesが読み込むテキストデータ、sg=1がskip-gramで学習することを示す(sg=0ならCBOW)、size=200がベクトルの次元数を200次元とすること、 min_count=1が1回未満登場する単語を破棄すること、window=3が学習時のwindow数(目的単語の周辺の何単語を推測するか)を表している。最終的な学習結果はmovie.modelというファイル名で保存される。
映画内容のベクトル化
次に単語ベクトルから文章のベクトルを作成する。今回は、単純に先程獲得した単語の分散表現を足し合わせた分散表現を、映画の内容を表すベクトルとしようと思う。
gensimで作成したモデルから単語のベクトルをロードするには、以下のようにモデルに引数を与えれば良い。
#ベクトルモデル読み込み
model = word2vec.Word2Vec.load('movie.model')
model['こんにちは']#こんにちはのベクトル
文章のベクトルを作成するに当たっては以下のようなコードで作成した。
from gensim.models import word2vec
import pandas as pd
import numpy as np
#ベクトルモデル読み込み
model = word2vec.Word2Vec.load('movie.model')
#pandas dataframe読み込み
df = pd.read_pickle('./morpho_data.pkl')
#データフレームにベクトル列を追加
df['vec'] = ''
print(df)
for i in range(len(df)):
#ベクトル用のndarray作成
vec = np.zeros(200)
#各ストーリーのセンテンスを読み込む
story = df.at[i, 'story'].split()
#各単語を読み込みベクトルを足し算していく
for word in story:
vec += model[word]
vec = vec.tolist()
df.at[i, 'vec'] = vec
#save as pickel file
df.to_pickle('./movie_vec.pkl')
これで映画のストーリーをベクトルで表現することができた。
レコメンデーションの検証
作成した映画あらすじベクトルを用いて映画のレコメンデーションを行うために、映画の類似度を測る指標としてコサイン類似度を使用した。コサイン類似度は2ベクトル間の角度を計算するもので、角度が小さいほど類似度が高く、cosθは1に近い値を示す。コサイン類似度の計算はnumpyを用いて簡単に計算することができる。
np.dot(vector1, vector2) / (np.linalg.norm(vector1) * np.linalg.norm(vector2))
今回は、作成したベクトルがどのような結果を示すのか検証するために、HEROKU上でwebアプリを公開した。フリーのdynoを利用しているため、初回起動に時間がかかる場合があるがご了承頂きたい。
バックトゥザフューチャーと、スターウォーズエピソード4のストーリーベクトルを足し合わせ、この合成ベクトルに近い値を持つ映画をレコメンドした。
 結果は下の画像のようになった。
結果は下の画像のようになった。
 スターウォーズエピソード5がレコメンデーションされたのは予測できたが、レイダース(インディ・ジョーンズ)やジュラシック ・ワールドなどがレコメンデーションされていた。スターウォーズのようなアクション映画特有のあらすじの書き方や、バックトゥザフューチャーの時代を股にかけるストーリーの特徴であるあらすじに年代が記載されるという特徴がこのような結果をもたらしたのかもしれない。
今回の結果を見てみると、あらすじの特徴をそれなりに反映した面白い結果が得られたように思う。また、分散表現の獲得方法をdoc2vecやBERTに変更することでより精度の良いレコメンデーションが可能だと思われる。これらの手法については今後試していこうと思う。
スターウォーズエピソード5がレコメンデーションされたのは予測できたが、レイダース(インディ・ジョーンズ)やジュラシック ・ワールドなどがレコメンデーションされていた。スターウォーズのようなアクション映画特有のあらすじの書き方や、バックトゥザフューチャーの時代を股にかけるストーリーの特徴であるあらすじに年代が記載されるという特徴がこのような結果をもたらしたのかもしれない。
今回の結果を見てみると、あらすじの特徴をそれなりに反映した面白い結果が得られたように思う。また、分散表現の獲得方法をdoc2vecやBERTに変更することでより精度の良いレコメンデーションが可能だと思われる。これらの手法については今後試していこうと思う。
本記事の内容に間違いがあったり、よりよい手法をご存知の場合はコメントしていただけるとありがたい。
Natural Language Processing from scratch #1
What is natural language ?
自然言語と言われてすぐにピンとくる人は多くないと思う。自然言語は、エスペラントなどの人工言語に対する自然発生した言語というわけではなく、アセンブリ言語やプログラミング言語のような各文が一義的な意味を表すコンピュータが理解するための人工言語と対比した、人が意思疎通のために利用する言語のことである。
自然言語は、同じ単語、文章でも文脈によって異なる意味を示すことが多々あり、さらに、時代の変遷により単語に新しい意味が生まれたり、新しい単語が生まれるため、自然言語の意味を正しくコンピュータに理解させるというタスクは非常に困難である。
Importance of NLP.
人類の知識は、文章によって保存され伝えられることが多いため(現にwikipediaには自然言語で書かれた無数の情報があるし、論文や特許は自然言語によって記述されている)、コンピュータが自然言語を理解することができれば、文明の発展に大きな影響を与えるような仕事をコンピュータにさせることもできるかもしれない。
コンピュータによる自然言語の理解=自然言語処理は、既にGoogleなどの検索機能や翻訳機能で使われている。あのGoogleの検索や翻訳に使われている自然言語処理ですらまだまだ完璧ではないことを考えると、自然言語処理について深い理解がある人材の需要は今後も増えていくと思われる。
今回は、単語の意味をコンピュータに理解させるための古典的な自然言語処理の手法について書いていきたいと思う。
ソースコードの全体はgithubに載せているため、要所部分の解説のみを行いたいと思う。
Thesaurus
コンピュータに単語の意味を理解させるための原始的な手法として、人手によって辞書を作成することが考えられる。これが、シソーラスと呼ばれるもので、グラフデータ構造によって単語間の関係性を定義している。
Pythonのnltkというライブラリを使用して、WordNetというシソーラスの構造を確認しようと思う。
まず、nltkをインストールする。
$ pip install nltk
次に、pythonインタプリンタを実行し、wordnetをダウンロードする。
>>> import nltk
>>> nltk.download('wordnet')
wordnetでmouseという単語にどのような関係性のネットワークが構築されているかを確認する。
>>> from nltk.corpus import wordnet
>>> wordnet.synsets('mouse')
[Synset('mouse.n.01'), Synset('shiner.n.01'), Synset('mouse.n.03'), Synset('mouse.n.04'), Synset('sneak.v.01'), Synset('mouse.v.02')]
この結果は、mouseという単語には、名詞に4つの意味グループが存在し、動詞に2つの意味グループが存在していることを表している。
例えば、'mouse.n.04'と同じ意味グループの単語は、以下のコマンドで見ることができる。
>>> wordnet.synset('mouse.n.04').lemma_names()
['mouse', 'computer_mouse']
mouseという名詞の4番目の意味グループには、'mouse', 'computer_mouse'という2つの単語があることが分かる。この2つの単語がどちらもコンピュータのHIDとしてのポインティングデバイスであるマウスを指していることは想像できるだろう。このようにシソーラスでは、単語が意味ごとの関係性によって分類・整理されている。
シソーラスは、コンピュータに単語の意味を理解させるという意味では、非常に優れた辞書だが、辞書は人手によって作成されているため、新語や新しい意味が誕生するたびに人の手によって辞書を整理し直す必要があり、英語だけでも100万語以上存在すると言われていることを鑑みると、コンピュータ用の辞書としては、シソーラスはあまり現実的な手法とは言えないだろう。
Vector based on word count
現在の自然言語処理の基礎となっているのが、機械的な処理によって単語を分散表現(ベクトル)で表すという手法である。単語を分散表現で表す手法にはさまざまな手法が考えられるが、最も基本的な、文章中の目標単語周辺に出現する単語をカウントすることで分散表現を獲得する手法について紹介する。これは、単語の意味は、その単語の周辺に存在する単語によって形成されるという考え方に基づいている。例えば、次のスティーブ・ジョブズの名言を見てみると、
You can’t connect the dots looking forward; you can only connect them looking backwards. So you have to trust that the dots will somehow connect in your future.
"connect"という単語は、"you"という単語の近くに出現している。これは"connect"が人に関係が深い単語であることを示唆していると考えられるだろう。また、"connect"は、"dots"という単語の近くにも出現している。これ、"connect"が複数のdotに関係する単語であることを表していると考えられるだろう。つまり、カウントの結果を集めることで、"connect"という単語が、人が主体となって行い、複数のモノに対して(結びつけるという)動作を行う単語であることを推察できる分散表現を獲得することができる。さらに、カウントの対象となる文章を増やすことにより、周辺に存在する単語の傾向がより明確になり、単語の意味がより正確に推測できる。
pythonで、カウントによる分散表現を計算する。
'''
単語出現頻度カウントによるベクトルの作成
'''
def count(all_words_num, id_text):
#記録用のテーブルを作成
table = [[0] * all_words_num for i in range(all_words_num)]
上記コードでは、単語の出現回数をカウントするためのリストを作成している。リストは、全語彙数文の要素数を持つリストを全語彙数分だけ用意している。
for k in id_text:
num_k = len(k)
for l in range(num_k):
element = table[k[l]]
if l == 0:#文章の開始単語の場合、右側単語のみを調べる
right = k[l+1]
element[right] += 1
elif l == num_k-1:#文章の終了単語の場合、左側単語のみを調べる
left = k[l-1]
element[left] += 1
else:#文章の途中の単語の場合、両側を調べる
left = k[l-1]
right = k[l+1]
element[left] += 1
element[right] += 1
return table
上記コードでは、注目単語周辺に存在した単語をリストに記録していき、forループによって、全文章文繰り返している。文章の開始単語は、当然左側に単語が存在しないため、右側のみをカウントし、文章の終了単語は、右側に単語が存在しないため、左側のみをカウントするために、if文によって処理を分岐させている。
最終的な結果は下のようになった。分散表現の各リストの登場
---入力テキスト---
---入力テキスト---
['you', 'can’t', 'connect', 'the', 'dots', 'looking', 'forward']
['you', 'can', 'only', 'connect', 'them', 'looking', 'backwards']
['so', 'you', 'have', 'to', 'trust', 'that', 'the', 'dots', 'will', 'somehow', 'connect', 'in', 'your', 'future']
---単語一覧---
('forward', 'future', 'your', 'looking', 'connect', 'can', 'will', 'have', 'the', 'can’t', 'backwards', 'in', 'so', 'trust', 'that', 'only', 'dots', 'them', 'you', 'somehow', 'to')
---分散表現---
forward : [0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
future : [0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
your : [0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
looking : [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0]
connect : [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0]
can : [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0]
will : [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0]
have : [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1]
the : [0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 2, 0, 0, 0, 0]
can’t : [0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0]
backwards : [0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
in : [0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
so : [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0]
trust : [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1]
that : [0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
only : [0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
dots : [0, 0, 0, 1, 0, 0, 1, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
them : [0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
you : [0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
somehow : [0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
to : [0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
入力文章を増やすことにより、単語ごとの傾向がより顕著となり、得られる分散表現の精度が高くなると思われる。
欠点としては、語彙数が増加するほど、ベクトルの次元数が大きくなるため計算量が増加してしまうという問題がある。この欠点を解消するためには、特異値分解SCDを用いた次元削減が用いられている。
また、他の欠点として、特定の単語との関係が薄い”the”などの単語に対して、"dots"という単語との結びつきが強いという誤った解釈がされていることが挙げられる。そこで、この欠点を解消する手法として、TF-IDFと呼ばれる手法がある。
次回は、SVDによる次元削減と、TF-IDFを用いたベクトルの重み付けについて書きたいと思う。
Ubuntu設定等のメモ
Ubuntuの環境をリセットするために再インストールすることが多いため(情弱)、設定を復元するための自分用メモを残しておく。
ログイン画面の背景変更
sudo vi /etc/alternatives/gdm3.css
下の記述を、
#lockDialogGroup {
background: #2c001e url(resource:///org/gnome/shell/theme/noise-texture.png);
background-repeat: repeat; }
下のように変更する。
#lockDialogGroup {
background: #2c001e url(file:///<用意した画像の場所>);
background-repeat: no-repeat;
background-size: cover;
background-position: center; }
ターミナルでファイルを開く
$ nautilus .(開きたいディレクトリ)
Hardware Programming with Chisel #1 Hello, Scala!

- 1. What is Hardware Programming?
- 2. Species of HDL.
- 3. About Chisel.
- 4. Install Scala.
- 5. Hello, World! with Scala.
1. What is Hardware Programming?
ハードウェアプログラミングは、ロジック回路をハードウェア記述言語(以下HDL:Hardware Description Language)によって実現する方法である。HDLは、電子回路の経時的振舞いと空間的構造を表現することで、ハードウェアの動作仕様を記述するための言語であり、半導体メーカーにおいて、ASIC(Application-Specific Integrated Circuit)やFPGA(Field-Programmable Gate Array)と呼ばれるLSI(Large Scale Integrated circuit)で所望の回路を実現するために用いられている。
最近では、Deep learningにおける並列計算を行うための専用回路を実装することで、消費電力を抑えつつ、学習や推論に掛かる時間を短縮するための専用回路(google社のTPUなど)開発のニーズが高まっていることもあり、Deep Learning技術に精通したソフトウェアエンジニアが、HDLを用いたハードウェアプログラミングを習得する必要に迫られることもあるのではないだろうか。
2. Species of HDL.
現在HDLで主流となっている言語には、Verilog HDLと、VHDLの2つがある。Verilog HDL、VHDLの双方とも1980年代に登場した言語であり、IEEEによって標準化されている。しかし、これらの言語は元々回路の動作使用の記述や回路シミュレーションを主目的として開発された言語のため、回路設計を主目的とするには若干不向きであることや、ソフトウェア開発用の言語(CやPythonなど)とは使い勝手が違うためソフトウェア開発者が学ぶにはハードルが高いといった欠点がある。
また高位合成と呼ばれる方法で、C言語等のソフトウェアプログラミング用ソースコードからハードウェアプログラミングを行うツールがxilinx社等により提供されているが、ソフトウェアプログラミング言語はあくまでも処理のフローを記述する言語であるため、効率的な回路を記述するためには結局、HDLにより設計する必要がある。
私自身ソフトウェアプログラミングの経験しかないため、このブログでは、回路設計を主目的とした言語かつ、ソフトウェアプログラミング言語ScalaのDSL(Domain-Specific Language)ライブラリであるChiselを用いてハードウェアプログラミングをしていきたいと思う。
3. About Chisel.
Chiselは2つのグループの開発者をターゲットにしている。
一つ目が、VHDLやVerilogに使い慣れており、ハードウェア生成のためにPythonやJavaを使用しているハードウェア設計者、もう一つが、プログラムの高速化等の目的で、ハードウェア設計に興味があるソフトウェアプログラマである。
Chiselは、オブジェクト指向や関数型言語といったデジタル設計におけるソフトウェアプログラミング言語のメリットを備えている。
なお、Chiselにおけるハードウェア設計では、テストや合成の中間言語としてVerilogが用いられているが、Chiselを使用する上で、Verilogの深い知識や理解は不要である。
4. Install Scala.
Chiselを使用するためにまずは、Scalaのインストール方法について紹介していく。Windowsや Macでのインストール方法については、各自Scalaの公式サイト等を参照して欲しい。
なお、この記事では、特に明示しない限りUbuntu 18.04.5上で作業している。
OpenJDKのインストール
scalaのプログラムやscala用のビルドツールは、JVM上で動作するため、JDKのインストールが必要である。
$ sudo apt install openjdk-8-jdk
sbt(scala build tool)のインストール
sbtはscalaのビルドや仮想環境・外部ライブラリの管理が行える便利なツールである。
$ echo "deb https://dl.bintray.com/sbt/debian /" | sudo tee -a /etc/apt/sources.list.d/sbt.list $ curl -sL "https://keyserver.ubuntu.com/pks/lookup?op=get&search=0x2EE0EA64E40A89B84B2DF73499E82A75642AC823" | sudo apt-key add $ sudo apt update $ sudo apt install sbt
これでScalaの開発環境が整った。
5. Hello, World! with Scala.
Scalaプログラミングの基本について書いていこうと思う。 まずはhello worldする。最初に作業用ディレクトリを作成する。
$ mkdir scala_tutorial $ cd scala_tutorial
次にプロジェクトのテンプレートを作成する。
$ sbt new scala/hello-world.g8
プロジェクトの名前を聞かれたら任意の名前をつける。今回は"hello-world"とした。
name [Hello World template]: hello-world
作成されたテンプレートは以下のような構成となっている。
.
├── hello-world
│ ├── build.sbt
│ ├── project
│ │ └── build.properties
│ └── src
│ └── main
│ └── scala
│ └── Main.scala
├── project
│ └── target
└── target
├── global-logging
└── task-temp-directory
10 directories, 3 files
作成されたテンプレートには最初からhello world!を表示するためのプログラムが作成されている(hello-world/src/main/scala/Main.scala)。 Hello Worldを表示するプログラムの中身は以下のようになっている。
object Main extends App {
println("Hello, World!")
}
1行目では、objectをMainと定義している。またextendsは、Appを継承していることを示している。この記述とすることにより、object内にmainメソッドを記述することなく、objectに記述されているコードを実行できる。printlnは末尾改行付き標準出力。 プロジェクトを実行するには以下のコマンドを入力する。なお初回実行時はコンパイルに多少の時間が掛かる。
$ sbt sbt:hello-world> run
実行結果
Hello, World!
次に簡単な数値計算を行ってみる。
object Main extends App {
val x = 2
val y = 3
var z = 0
println("z:"+z)
z = x + y
println("z:"+z)
}
Pythonは型推定の機能があるため、変数に型の宣言は必要ないが、scalaでは変数の型を明示的に宣言する必要がある。valは再代入することができない変数の宣言、varは再代入することが可能な変数の宣言である。
上記のプログラムの実行結果は以下の通り。
z:0 z:5
最初に出力されたzは代入前の初期値である0の値を保持しており、2回目に出力されたzは、x+yの計算結果を保持していることが分かる。
次にif式とfor式を試してみる。プログラミングにおいて式は計算結果の値を返すモノ、文は評価は行うが値を返さないモノを意味している。つまりifやforは値を返すことができる。ただしこの記事では、式であることが重要であるようなプログラムは作成しない。
if式とfor式を試すために、1から15まで順に変数iに代入し、iの値が3の倍数であればfizzと表示し、5の倍数であればfuzzと表示、15の倍数であればfizzbuzzと表示、いずれの倍数でもなければiの値を表示するプログラムを作成する。
object Main extends App {
var n = 15
for{i <- 1 to n}{
if(i%15==0){
println("FizzBuzz")
} else if(i%3==0){
println("Fizz")
} else if(i%5==0){
println("Buzz")
}else{
println(i)
}
}
}
3行目は、iが1からnまで1つずつインクリメントして{}内のプログラムを繰り返し実行する。※インクリメント数を変更する場合は、 for{i <- (1 to n by 2)}のように「by 値」を追加する。
if式では()無いの式がTrueであるとき、{}内のプログラムを実行する。else ifには複数条件式を設定する場合、elseにはいずれの条件にも合致しなかった場合の処理を記述する。
実行結果
1 2 Fizz 4 Buzz Fizz 7 8 Fizz Buzz 11 Fizz 13 14 FizzBuzz
以上でscalaの基本的な文法紹介は終わりにして、次回以降はChiselの環境構築及びプログラミングについて書きたいと思う。
| 【送料無料】 Scalaスケーラブルプログラミング 第3版 / マーティン・オダースキー 【本】 価格:5,060円 |
![]()
| 【POD】Chiselを始めたい人に読んで欲しい本 (技術の泉シリーズ(NextPublishing)) [ 七夕 雅俊 ] 価格:2,750円 |
![]()